El código fuente de referencia está disponible aquí.
1. Ejemplo Práctico: Filtro de Autenticación
El objetivo del filtro es asegurar que las páginas sólo estén disponibles para usuarios que han superado exitosamente el proceso de autenticación. Sin un filtro, este requerimiento implica la intervención de todas las páginas .jsp de la aplicación (asumamos por un momento que no se está trabajando con ningún framework específico que ya provea esta funcionalidad).
Para efectos del ejemplo, consideraremos un sitio web muy simple, en adelante "minisitio" (como dicen los abogados), que tiene una página con contenido (index.jsp) y una página de ayuda (ayuda.jsp). La página index.jsp está restringida para los usuarios autenticados correctamente. La página ayuda.jsp no requiere usuarios autenticados para acceder a ella. El flujo típico de autenticación de usuarios es el que se muestra en el siguiente diagrama. Las páginas del lado izquierdo requieren usuarios autenticados. Las páginas del lado derecho no.
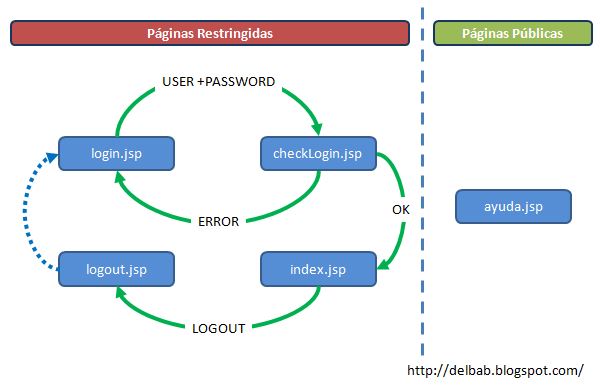
Hay múltiples maneras de resolver la autenticación de usuarios. Para efectos de este ejemplo, la autenticación exitosa será registrada utilizando las variables de sesión del contexto. En términos simples, si un usuario se autenticó correctamente, se marcará la variable "logged" de la sessión con el valor "true".
Considerando el diagrama anterior, el flujo es como sigue:
- Usuario ingresa a la página login.jsp, ingresa su usuario y password y pulsa el botón Ingresar.
- Los datos son enviados a la página checkLogin.jsp que valida si el usuario es válido contra algún sistema (base de datos, archivo, etc.)
- Si no es válido, reenvía al usuario al paso 1 con un mensaje descriptivo del error.
- Si es válido, se registra el valor "true" en la variable "logged" de la sesión.
- El usuario puede acceder a la página de contenido index.jsp.
- Cuando el usuario quiere salir del sistema, es enviado a la página logout.jsp que invalida la sesión.
- El usuario es redirigido a la página login.jsp.
Sin el uso de un filtro, la validación de los usuarios autenticados en las páginas restringidas implicaría agregar el código para validar la información de la sesión en cada página. Si bien es cierto esto se puede hacer reutilizando código por medio de includes, funciones, bibliotecas, etc., no es una estrategia que permita crecer en el tiempo. Un ejemplo simple de este enfoque es que la responsabilidad de agregar la validación queda en manos del desarrollador. Si el desarrollador olvida incorporar el código que valida la sesión, la página quedará expuesta a usuarios no autenticados.
4. Validación con Filtro
Veamos ahora cómo implementar un filtro para validar el acceso a las páginas restringidas del minisitio descrito anteriormente.
4.1 Configuración del Filtro
Considerando el flujo de autenticación descrito previamente (algo así como los requerimientos), hay algunas páginas que deben tener autenticación y otras que no. La página ayuda.jsp es, por definición, una página que no requiere usuarios autenticados, sin embargo, las páginas login.jsp, checkLogin.jsp y logout.jsp tampoco requieren usuarios autenticados. No tiene mucho sentido exigir un usuario autenticado para la página de login por ejemplo. Lo mismo sucede con las otras. Por otra parte, cuando el filtro detecte el acceso de un usuario no autenticado a una página restringida, debe saber a qué página debe enviar al usuario para que se autentique. En el caso del minisitio, la página es login.jsp, sin embargo, podría ser necesario modificar esta página dinámicamente.
Para cumplir con lo anterior, se considera la definición de dos parámetros (exclude y loginPage) en la configuración del filtro para permitir modificar este comportamiento dinámicamente. La configuración, será como sigue en el archivo web.xml.
<filter>
<filter-name>LoginFilter</filter-name>
<filter-class>cl.abertini.filters.LoginFilter</filter-class>
<init-param>
<param-name>exclude</param-name>
<param-value>/login.jsp ... /ayuda.jsp</param-value>
</init-param>
<init-param>
<param-name>loginPage</param-name>
<param-value>/login.jsp</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>LoginFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
4.2 Construcción del Filtro
Como se mencionó en la primera parte, el filtro se construye heredando de la clase javax.servlet.Filter y se deben implementar los métodos siguientes init(...), doFilter(...) y destroy(). A continuación se describe la implementación realizada en el contexto del ejemplo.
- init(FilterConfig filterConfig)
El método, básicamente, lee la configuración del archivo web.xml y rescata la información de los parámetros exclude (páginas que no requieren usuarios autenticados) y loginPage (la página que permite a un usuario autenticarse).
La configuración se almacena en las variables sExclude y sLoginPage de la clase para ser utilizadas en el método doFilter(...). - doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
Este es el método principal y que será ejecutado cada vez que se acceda a una página del contexto.
En términos simples, primero se valida que la página a la que se está accediendo no sea una página excluida. En caso de serlo, se pasa el control al siguiente filtro de la cadena (secuencia) por medio de la instrucción chain.doFilter( request, response ).
En caso de no ser una página excluida, se valida si el atributo "logged" está en la sessión. Para efectos del ejemplo, sólo se valida que exista y no necesariamente que tenga el valor "true".
Si el atributo no existe, se redirige la respuesta a la página configurada como loginPage. Notar que en este caso, no se traspasa el procesamiento a ningún filtro de la cadena una vez que se reenvió al usuario a la página indicada.
En caso contrario, es decir, que el atributo "logged" existe, simplemente se traspasa el control al siguiente filtro como se explicó anteriormente. - destroy()
En este ejemplo, dado que la información que administra el filtro (parámetros exclude y loginPage) no consumen muchos recursos, no se realiza nada. Si el filtro que se esté implementado, requiriera administrar grandes cantidades de memoria y/o estructuras de datos complejas y/o cachés o similares, entonces, en este método se debieran implementar los procedimientos para asegurar una correcta destrucción (y almacenamiento tal vez) de la información.
Para probar el código anterior, se requiere tener instalado Tomcat 6.X ó superior. Se debe habilitar el contexto en el directorio webapps y levantar el servidor. Una vez levantado, se debiera poder ver el sitio en la siguiente URL:
http://localhost:8080/testSite/login.jsp
Para probar que el filtro está operativo, se puede intentar acceder a la página restringida, con la siguiente URL:
http://localhost:8080/testSite/index.jsp
Si es que no se ha realizado el proceso de autenticación, el filtro debiera bloquear el acceso y reenviar el browser a la página de login. Por el contrario, si se accede a la página de ayuda, no debiera haber problemas ya que está definida como una página sin acceso restringido. Para acceder a esta página, se debe utilizar la siguiente URL:
http://localhost:8080/testSite/ayuda.jsp
Para probar la autenticación, se debe usar la palabra "prueba" como usuario y password en la página de login. Si se ingresan los datos correctos, se debiera poder acceder a la página index.jsp sin problemas.
6. Más Filtros y Extensiones
La distribución estándar de Tomcat 7 incluye varios filtros. En términos generales, los filtros provistos proveen funcionalidades destinadas a mejorar la seguridad del sitio (XSS, CSRF), algunos para depuración y otros para manipular aspectos del HTML entregado al cliente (encoding por ejemplo).
En la siguiente página de Oracle hay una muy buena descripción de la infraestructura de filtros y algunos ejemplos interesantes.
The Essentials of Filters
De todos los ejemplos que he visto al respecto, el siguiente me parece el mejor para demostrar las capacidades de los filtros. El filtro descrito permite reducir el tamaño del HTML entregado al cliente eliminando algunas secuencias como espacios, líneas en blanco, etc. Es interesante porque muestra un truco para poder "capturar" la respuesta (HTML) que va a ser entregada al cliente, como parte del flujo de salida de la cadena (secuencia) de filtros (ver punto 3.2 de la primera parte). Una extensión de este mecanismo sería la construcción de un modelo simple de templates.
Minifying HTML in the Servlet container
7. Conclusiones
La próxima vez que se vaya a implementar una funcionalidad transversal a un sitio, es recomendable analizar si aplica al construcción de un filtro o no. En esta consideración, más allá de las cosas operativas y las precauciones que se pudieran tomar como parte del proceso de desarrollo, la más importante es la posibilidad de asegurar que ciertas funcionalidades se apliquen sin necesidad de depender de la "buena voluntad" de los desarrolladores. Esto, a la larga, no sólo simplifica el proceso si no que, además, asegura que los desarrolladores se focalicen en el desarrollo de las páginas y sus objetivos. Las condiciones higiénicas asociadas ya van a estar implementadas.



